
Rubyで実働時間を測って顧客にタイムチャージしよう!
仕事の生産性を上げるためには時間管理は重要です。きちっとした時間管理ができてこそ、プロフェッショナルと言えるでしょう。欧米の弁護士の報酬は多くはタイムチャージとなっていて、彼らは案件ごとの実働時間をカウントして、それに自分の単価を掛けて顧客に請求します。
やっぱり、プロフェッショナルのやることは違いますね^ ^;
したがってあなたがプロフェッショナルと認められるようになるためには、たとえあなたの報酬がその労働時間に依存していなくとも、案件ごとに使った時間をきっちりと数えて、あなたの報酬額と実働時間の関係を常日頃から意識することが重要です..
そんなわけで..
私もプロフェッショナルを目指して、今日から実働時間を計測したいと思います:)
実働時間の計測には次のステップが必要です。
- 案件ごとの開始・終了時間を毎日記録する
- 案件ごとに時間を集計する
案件ごとの開始・終了時間を毎日記録する
案件に対する実働時間というのは一日のうちでも小間切れになるので、これを記録するのはなかなか面倒です。よって時間の記録をできるだけ簡単に行えるようにする必要があります。
そうなるとやっぱりテキストファイルに単純なフォーマットで記録するのがいいです。例えばこんな感じで。
<案件名>
<開始日時> - <終了日時>
<開始日時> - <終了日時>
<開始日時> - <終了日時>
<開始日時> - <終了日時>
<案件名>
<開始日時> - <終了日時>
<開始日時> - <終了日時>
<開始日時> - <終了日時>
<開始日時> - <終了日時>日時の入力は面倒ですが、私はVimを使うので.vimrcに以下を追加して省力化します。
" insert timestamp
map <D-F2> <ESC>:r !date<CR>これでcmd+F2で日時が打てるようになります。
こんなイメージです。
AA123
Sat Jan 21 08:57:36 JST 2012 - Sat Jan 21 12:00:00 JST 2012
Sat Jan 21 14:24:14 JST 2012 - Sat Jan 21 15:10:17 JST 2012
Sun Jan 22 07:33:36 JST 2012 - Sun Jan 22 10:47:47 JST 2012
Sun Jan 22 14:22:24 JST 2012 - Sun Jan 22 18:39:39 JST 2012
Tue Jan 24 10:13:54 JST 2012 - Tue Jan 24 12:07:55 JST 2012
Tue Jan 24 13:08:44 JST 2012 - Tue Jan 24 15:19:13 JST 2012
Tue Jan 24 16:38:05 JST 2012 - Tue Jan 24 18:15:15 JST 2012
Project-XYZ
Sat Feb 11 08:57:36 JST 2012 - Sat Feb 11 11:00:00 JST 2012
Sat Feb 11 18:11:36 JST 2012 - Sat Feb 11 19:00:00 JST 2012
Sun Feb 12 08:33:36 JST 2012 - Sun Feb 12 10:47:47 JST 2012
Sat Feb 13 12:44:14 JST 2012 - Sat Feb 13 18:30:17 JST 2012
Sat Feb 13 22:24:24 JST 2012 - Sat Feb 14 01:50:07 JST 2012案件ごとに時間を集計する
さあ仕事が終わったら上のファイルをRubyに読み込ませて集計しましょう。
次のような出力が見やすくていいですね。
AA123
Sat Jan 21 08:57:36 JST 2012 - Sat Jan 21 12:00:00 JST 2012
Sat Jan 21 14:24:14 JST 2012 - Sat Jan 21 15:10:17 JST 2012
Sun Jan 22 07:33:36 JST 2012 - Sun Jan 22 10:47:47 JST 2012
Sun Jan 22 14:22:24 JST 2012 - Sun Jan 22 18:39:39 JST 2012
Tue Jan 24 10:13:54 JST 2012 - Tue Jan 24 12:07:55 JST 2012
Tue Jan 24 13:08:44 JST 2012 - Tue Jan 24 15:19:13 JST 2012
Tue Jan 24 16:38:05 JST 2012 - Tue Jan 24 18:15:15 JST 2012
Project-XYZ
Sat Feb 11 08:57:36 JST 2012 - Sat Feb 11 11:00:00 JST 2012
Sat Feb 11 18:11:36 JST 2012 - Sat Feb 11 19:00:00 JST 2012
Sun Feb 12 08:33:36 JST 2012 - Sun Feb 12 10:47:47 JST 2012
Sat Feb 13 12:44:14 JST 2012 - Sat Feb 13 18:30:17 JST 2012
Sat Feb 13 22:24:24 JST 2012 - Sat Feb 14 01:50:07 JST 2012次のような方針にしましょう。
- ファイルを案件ごとに分ける。
- 日時のラインをパースして日にちごとの時間に集計する。
- フォーマットを用意して集計データを出力する。
ファイルを案件ごとに分ける
split_by_projectメソッドを定義します。
def split_by_project(lines, time_pattern=/JST/)
lines.map(&:chomp)
.reject(&:empty?)
.chunk { |line| !line.match(time_pattern) }
.each_slice(2)
.map { |(_,names), (_,timelines)| [names.last, timelines] }
endこのメソッドは読み込んだファイルの各行に対し、改行を除去し(chomp)、空行を除去し(empty?)、日時の行の前後で行分割し(chunk)、案件名と日時行をセットとし(each_slice(2))、最後に、案件名と日時行の配列を返します(map)。
chunkでは日時行を識別するために、/JST/をパターンとしていますが、第2引数に任意のパターンを取ることができます。
出力は次のようになります。
split_by_project(ARGF) # => [["AA123", [" Sat Jan 21 08:57:36 JST 2012 - Sat Jan 21 12:00:00 JST 2012", " Sat Jan 21 14:24:14 JST 2012 - Sat Jan 21 15:10:17 JST 2012", " Sun Jan 22 07:33:36 JST 2012 - Sun Jan 22 10:47:47 JST 2012", " Sun Jan 22 14:22:24 JST 2012 - Sun Jan 22 18:39:39 JST 2012", " Tue Jan 24 10:13:54 JST 2012 - Tue Jan 24 12:07:55 JST 2012", " Tue Jan 24 13:08:44 JST 2012 - Tue Jan 24 15:19:13 JST 2012", " Tue Jan 24 16:38:05 JST 2012 - Tue Jan 24 18:15:15 JST 2012"]], ["Project-XYZ", [" Sat Feb 11 08:57:36 JST 2012 - Sat Feb 11 11:00:00 JST 2012", " Sat Feb 11 18:11:36 JST 2012 - Sat Feb 11 19:00:00 JST 2012", " Sun Feb 12 08:33:36 JST 2012 - Sun Feb 12 10:47:47 JST 2012", " Sat Feb 13 12:44:14 JST 2012 - Sat Feb 13 18:30:17 JST 2012", " Sat Feb 13 22:24:24 JST 2012 - Sat Feb 14 01:50:07 JST 2012"]]]日時のラインをパースして日にちごとの時間に集計する
次にparse_and_arrange_timelinesメソッドを定義します。
require 'date'
def parse_and_arrange_timelines(timelines, spliters=%w(- =>))
timelines.map { |line|
from, to = line.split(/\s*#{spliters.join('|')}\s*/)
.map { |str| DateTime.parse str }
[from.to_date.to_s, to-from]
}.inject(Hash.new(0)) { |h, (date, lap)| h[date] += lap; h }
endこのメソッドは、split_by_projectで生成された日時行を開始日時と終了日時に分けて(split)、DateTimeオブジェクトに変換し(DateTime.parse)、日付のラベルと経過時間の配列とし(map)、さらに、日付ごとの経過時間に集計します(inject)。
ここでは規定のspliterを’-‘, ‘=>’としていますが、第2引数に任意のspliterを取ることができます。
出力は次のようになります。
timelines = split_by_project(DATA)[0][1] # => [" Sat Jan 21 08:57:36 JST 2012 - Sat Jan 21 12:00:00 JST 2012", " Sat Jan 21 14:24:14 JST 2012 - Sat Jan 21 15:10:17 JST 2012", " Sun Jan 22 07:33:36 JST 2012 - Sun Jan 22 10:47:47 JST 2012", " Sun Jan 22 14:22:24 JST 2012 - Sun Jan 22 18:39:39 JST 2012", " Tue Jan 24 10:13:54 JST 2012 - Tue Jan 24 12:07:55 JST 2012", " Tue Jan 24 13:08:44 JST 2012 - Tue Jan 24 15:19:13 JST 2012", " Tue Jan 24 16:38:05 JST 2012 - Tue Jan 24 18:15:15 JST 2012"]
parse_and_arrange_timelines(timelines) # => {"2012-01-21"=>(1523/9600), "2012-01-22"=>(13543/43200), "2012-01-24"=>(205/864)}経過時間はRationalで表されています。
フォーマットを用意して集計データを出力する
最後に、出力用のフォーマットメソッドformat_forを用意します。
require "term/ansicolor"
def format_for(name, times_by_date, w=20)
times = times_by_date.map { |date, fractime| [date, frac2time(fractime)] }
total = frac2time times_by_date.map(&:last).inject(:+)
[
"#{name}:".cyan,
times.map { |date, time| "#{date}: #{time}".rjust(w) }.sort,
"Total: #{total}".rjust(w).magenta,
"-"*w
]
end
def frac2time(fractime, opt=[:h,:m])
label = [:h, :m, :s, :f]
hmsf = Date.send(:day_fraction_to_time, fractime)
Hash[label.zip hmsf].select { |k, v| opt.include? k }
.values.map { |v| format "%02d", v }.join(':')
endこのメソッドは案件名と日付ごとの集計時間を取って、経過時間をhr:min:secのフォーマットに変換し(frac2time)、総経過時間を計算し(total)、rjustを使って出力用にフォーマットします。折角ですからterm-ansicolorで色付けしています。
さあ、これらをまとめて実働時間を集計するworktime.rbの完成です!
出力はこんな感じになります!
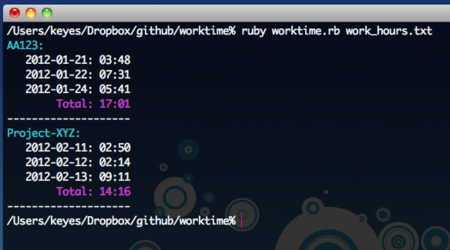
これであなたも私もプロフェッショナル道まっしぐらですね!
blog comments powered by Disqus
