
Rubyチュートリアル ─ 英文小説の最頻出ワードを見つけよう! ─(その4)
この記事は、─ 電子書籍「Rubyチュートリアル ~英文小説の最頻出ワードを見つけよう!」EPUB/MOBI版─の公開第4弾です(第1弾はこちら)。本書第2章のバージョン22以降を掲載しています。
電子書籍版は、タブレット端末向けのEPUBとKindle向けのMOBI形式を用意しています。もちろんデスクトップ向けのEPUBリーダー(Kitabu他)およびKindleリーダーも提供されていますので、本書をPCまたはMacで読むこともできます。100円と大変お求めやすい価格になっておりますので、ご購入検討頂けましたら大変に嬉しく思いますm(__)m

電子書籍「Rubyチュートリアル ~英文小説の最頻出ワードを見つけよう!」EPUB/MOBI版
(目次)
序章
1章 Rubyの特徴
Rubyはオブジェクト指向です
Rubyのブロックは仮装オブジェクトです
クラスはオブジェクトの母であってクラスの子であるオブジェクトです
Rubyはユーザフレンドリです
2章 最頻出ワードを見つける
バージョン01(最初の一歩)
バージョン02(処理の分離)
バージョン03(injectメソッド)
バージョン04(sort_byメソッド)
バージョン05(takeメソッド)
バージョン06(take_byメソッドの定義)
バージョン07(Enumerable#take_byの定義)
バージョン08(top_by_valueの定義)
バージョン09(top_by_valueの改良)
バージョン10(DRY原則)
バージョン11(block_given?メソッド)
バージョン12(DRY再び)
バージョン13(block_given?の移動)
バージョン14(ARGF.take_wordsの定義)
バージョン15(make_freq_dicの定義)
バージョン16(スクリプトのクラス化)
バージョン17(top_by_lengthの定義)
バージョン18(DRY三度)
バージョン19(入力の拡張)
バージョン20(ネットアクセス)
バージョン21(メソッドの追加)
バージョン22(出力形式の再考)
バージョン23(pretty_printの定義)
バージョン24(GUI版)
バージョン25(クラスの拡張)
バージョン26(他の演算メソッドの定義)
バージョン27(DRY四度)
バージョン28(ユニークワードの抽出)
バージョン29(仕上げ)
終章
謝辞
バージョン22(出力形式の再考)
っと、その前に…
アウトプットのしょぼさに今さらながら気が付いてしまいました。
wdic = WordDictionary.new(ARGF)
p wdic.top_by_frequency(20)
#> [["the", 16077], ["of", 9823], ["and", 7482], ["to", 7098], ["in", 4456], ["a", 3841], ["that", 3161], ["was", 3040], ["it", 2919], ["i", 2881], ["her", 2550], ["she", 2313], ["as", 2134], ["you", 2071], ["not", 2057], ["be", 2044], ["is", 2033], ["his", 2009], ["he", 1940], ["for", 1927]]これが上司に対する報告か何かの類いのものならまず却下です。これをもう少しマシなものにしましょう。
wdic = WordDictionary.new(ARGF)
wdic.top_by_frequency(20).each { |word, freq| puts "#{freq}:#{word}" }
#>
16077:the
9823:of
7482:and
7098:to
4456:in
3841:a
3161:that
3040:was
2919:it
2881:i
2550:her
2313:she
2134:as
2071:you
2057:not
2044:be
2033:is
2009:his
1940:he
1927:forこれだけでも大分よくなりました。しかし上司はもっと視覚的にアピールするものを好むでしょうね。
バージョン23(pretty_printの定義)
単語の出現数を*の数で視覚化する、pretty_printメソッドを定義しましょう。
def pretty_print(data)
max_stars = 60
max_value = data.max_by { |key, val| val }.slice(1)
data.each do |word, freq|
stars = "*" * (max_stars * (freq/max_value.to_f)).ceil
printf "%5d:%-5s %s\n", freq, word, stars
end
end
wdic = WordDictionary.new(ARGF)
pretty_print wdic.top_by_frequency(20)出力は次のようになります。
16077:the ************************************************************
9823:of *************************************
7482:and ****************************
7098:to ***************************
4456:in *****************
3841:a ***************
3161:that ************
3040:was ************
2919:it ***********
2881:i ***********
2550:her **********
2313:she *********
2134:as ********
2071:you ********
2057:not ********
2044:be ********
2033:is ********
2009:his ********
1940:he ********
1927:for ********いい感じですね。
prinftを使って出力をフォーマットしています。フォーマットについては、公式マニュアルの以下の頁が参考になります。
module function Kernel.#format
バージョン24(GUI版)
「おいおい未だにCUIかよ!」
いつか言われると思いました。
だから先回りして、GUI版を用意しておきました。
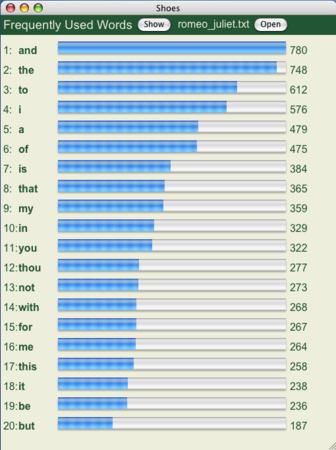
ShoesというRubyのGUIフレームワークで書いています。もちろんWordDictionaryクラスで生成したオブジェクトを使い、Shoesではその描画だけをしています。Openで対象ファイルを開き、Showでグラフが描画されます。
実装は褒められたものじゃありませんが、これも合せて公開しておきます。実行にはShoesのインストールが必要です。
Shoes! The easiest little GUI toolkit, for Ruby.
バージョン25(クラスの拡張)
さてGUIで出力も魅力的なものになりました。もうやり残すことはなさそうです。当初単なる制御構造であったスクリプトが、WordDictionaryという立派なクラスになりました。これで将来このクラスを拡張したり、このクラスをベースにしたアプリケーションを作れます。
で、将来っていつ?
…
そうです。DogYearのこの時代に、いつ来るか分からない将来を待っているゆとりなんて私たちにはないのです!自分たちから未来に向かって進むのです!何らかの形ある結果を残すのです!!
…
ということで…
なんか息巻いている人がいるので、もう少し進みましょう。 まずはもう少し機能拡張しましょう。WordDictionaryクラスから生成した複数の単語辞書オブジェクトを、相互作用させるような機能があったら楽しそうです。
まずは2つのオブジェクトを結合する +メソッドを定義しましょう。
class WordDictionary
attr_reader :words
def +(other)
result = (@words + other.words).join(" ")
WordDictionary.new(result)
end
protected :words
end+メソッドは他の単語辞書オブジェクトを引数に取って、自身と引数の単語を結合した単語辞書オブジェクトを返します。つまりAオブジェクトにrubyという単語が32個あり、Bオブジェクトに18個あった場合、これらを結合したCオブジェクトにはrubyは50個あることになります。
attr_reader :wordsは、+メソッドの実装において他のオブジェクトの@wordsインスタンス変数にアクセスできるようにします。protected :wordsにおいてその可視性を、同系のオブジェクトからのアクセスに限定します。
+メソッドのresultには2つの単語オブジェクトの単語をスペースで結合してなる文字列が入り、その文字列でWordDictionaryクラスのオブジェクトを作って返り値とします。@wordsは配列を指していますから、実装においては配列の+メソッドが使えます。
これによって通常の算術演算のような記法で、2つの単語辞書オブジェクトを結合できるようになりました。
alice = WordDictionary.new('public/alice.txt')
romeo_juliet = WordDictionary.new('public/romeo_juliet.txt')
p alice.top_by_length(10) { |val| val > 10 }
p romeo_juliet.top_by_length(10) { |val| val > 10 }
p (alice + romeo_juliet).top_by_length(10) { |val| val > 10 }
#> [["caterpillar", 28, 11], ["everything", 14, 10], ["adventures", 12, 10], ["foundation", 25, 10], ["electronic", 27, 10], ["paragraph", 11, 9], ["anxiously", 14, 9], ["beautiful", 13, 9], ["agreement", 18, 9], ["trademark", 11, 9]]
#> [["distributed", 18, 11], ["shakespeare", 17, 11], ["electronic", 19, 10], ["therefore", 23, 9], ["gentleman", 14, 9], ["gutenberg", 24, 9], ["gentlemen", 11, 9], ["copyright", 16, 9], ["benvolio", 17, 8], ["daughter", 17, 8]]
Argument has assumed as a text string
#> [["distribution", 16, 12], ["shakespeare", 18, 11], ["caterpillar", 28, 11], ["opportunity", 11, 11], ["information", 13, 11], ["distributed", 22, 11], ["everything", 15, 10], ["adventures", 12, 10], ["foundation", 25, 10], ["permission", 16, 10]]バージョン26(他の演算メソッドの定義)
| じゃあ次に-メソッドを定義しましょう。ついでに&メソッドと** | メソッドも定義しましょう。 **-メソッドは2つのオブジェクトの差分を、&メソッドと** | メソッドはそれぞれそれらの積と和を出力します。なお先のrubyの例を-**メソッドに適用した場合、Cオブジェクトのrubyの個数は14でなく0になります。 |
class WordDictionary
attr_reader :words
def +(other)
result = (@words + other.words).join(" ")
WordDictionary.new(result)
end
protected :words
def -(other)
result = (@words - other.words).join(" ")
WordDictionary.new(result)
end
def &(other)
result = (@words & other.words).join(" ")
WordDictionary.new(result)
end
def |(other)
result = (@words | other.words).join(" ")
WordDictionary.new(result)
end
endバージョン27(DRY四度)
さて次にやるべきことは分かってますね?そう、Don’t Repeat Yourself!です。
上の4つの演算はその中の演算子が異なるだけです。先の例のようにこれをブロックやオブジェクト化して渡す方法がありますが、ここではもっとスマートにシンボルを使って渡してみましょう。
class WordDictionary
attr_reader :words
def +(other)
arithmetics(:+, other)
end
def -(other)
arithmetics(:-, other)
end
def &(other)
arithmetics(:&, other)
end
def |(other)
arithmetics(:|, other)
end
private
def arithmetics(op, other)
result = (@words.send op, other.words).join(" ")
WordDictionary.new(result)
end
endarithmeticsメソッド内でsendメソッドを使っている点がポイントです。sendメソッドは、シンボルで表現されたメソッドを実行できるようにします。これでコードがすっきりしました。
バージョン28(ユニークワードの抽出)
さてこれらの演算子を使って何かしたいですね…
いいのを思いつきました。
ある小説を元にしたオブジェクトから、基本単語からなるオブジェクトを差し引けば、その小説にユニークな単語が抽出できるかもしれません。
class WordDictionary
def select(regexp)
text =
@freq_dic.select { |word, freq| word =~ regexp }
.select { |word, freq| block_given? ? yield(freq) : freq }
.map { |word, freq| "#{word} " * freq }
.join(" ")
WordDictionary.new(text, true)
end
def uniq_words(n, *base)
base.inject(self) { |_self, b| _self - b.select(/./) { |freq| freq >= 10 } }.top_by_frequency(n)
end
enduniq_wordsは個数nと複数の基本単語オブジェクトbaseを取って、そのオブジェクトに固有のワードトップnを出力します。injectメソッドのブロックの中で先ほど定義した-メソッドを使っています。
ここでselectメソッドを使ってbaseオブジェクトにおける、対象単語をその頻度が10以上のものに限定することで、baseオブジェクトにおけるゴミ(基本単語でないもの)をある程度排除するようにしています。そのためselectメソッドをブロックを取れるように修正しました。
さて、早速「不思議の国のアリス」のユニークなワードを出力してみましょう。
if $0 == __FILE__
base = WordDictionary.new('public/base.txt')
alice = WordDictionary.new('public/alice.txt')
p alice.uniq_words(40, base)
end
># Argument has assumed as a text string
># Argument has assumed as a text string
># [["alice", 403], ["turtle", 59], ["mock", 56], ["hatter", 56], ["gryphon", 55], ["rabbit", 51], ["got", 45], ["mouse", 44], ["duchess", 42], ["tone", 40], ["dormouse", 40], ["cat", 37], ["hare", 31], ["caterpillar", 28], ["jury", 22], ["sort", 20], ["tea", 19], ["soup", 18], ["bill", 17], ["hastily", 16], ["bit", 16], ["doesn", 16], ["didn", 14], ["dinah", 14], ["anxiously", 14], ["baby", 14], ["footman", 14], ["trying", 14], ["cook", 13], ["wouldn", 13]]なんかいい感じじゃないですか!
なお最後のif $0 == __FILE__ はこのスクリプトを他のスクリプトからrequireしたときにはこの部分が、require先で実行されないようにするための技法です。$0はrubyインタプリタに渡したスクリプト名__FILE__はこのスクリプト名を参照します。
バージョン29(仕上げ)
でも、さっきからうっとうしい文字が一緒に出力されていますね。オブジェクトを内部で再構築するとき文字列を渡すのでそれが原因です。フラグを立ててこれに対処します。
WordDictionaryクラス内部でオブジェクトを生成するときはinner_callにtrueを渡して、”Argument has…“のメッセージがでないようにします。
ついでに最後の仕上げとして、クラスは入力データの名前nameを受け取れるようにし、また総単語種数を出力するsizeメソッドも定義しましょう。
class WordDictionary
att_reader :words, :name
def initialize(input, name="none", inner_call=false)
input = input_to_string(input, inner_call)
@name = name
end
def select(regexp)
text = @freq_dic.select { |word, freq| word =~ regexp }.select { |word, freq| block_given? ? yield(freq) : freq }.map { |word, freq| "#{word} " * freq }.join(" ")
WordDictionary.new(text, @name, true)
end
def size
@freq_dic.length
end
private
def input_to_string(input, inner_call)
case input
when String
begin
File.open(input, "r") { |f| return f.read }
rescue
puts "Argument has assumed as a text string" unless inner_call
input
end
end
end
def arithmetics(op, other)
result = (@words.send op, other.words).join(" ")
WordDictionary.new(result, '', true)
end
endさあこれで完成です!完成したスクリプト全体を眺めてみましょう。
require "open-uri"
module Enumerable
def take_by(nth)
sort_by { |elem| yield elem }.slice(0...nth)
end
end
class WordDictionary
include Enumerable
attr_reader :name, :words
def initialize(input, name= 'none', inner_call=false)
input = input_to_string(input, inner_call)
@words = input.downcase.scan(/[a-z']+/)
@freq_dic = @words.inject(Hash.new(0)) { |dic, word| dic[word] += 1 ; dic }
@name = name
end
def each
@freq_dic.each { |elem| yield elem }
end
def top_by_frequency(nth, &blk)
take_by_value(nth, lambda { |v| -v }, &blk)
end
def bottom_by_frequency(nth, &blk)
take_by_value(nth, lambda { |v| v }, &blk)
end
def top_by_length(nth, &blk)
list = take_by_key(nth, lambda { |word| -word.length }, &blk)
list.map { |word, freq| [word, freq, word.length] }
end
def select(regexp)
text = @freq_dic.select { |word, freq| word =~ regexp }.select { |word, freq| block_given? ? yield(freq) : freq }.map { |word, freq| "#{word} " * freq }.join(" ")
WordDictionary.new(text, @name, true)
end
def to_s
@freq_dic.to_s
end
def size
@freq_dic.length
end
def +(other)
arithmetics(:+, other)
end
def -(other)
arithmetics(:-, other)
end
def &(other)
arithmetics(:&, other)
end
def |(other)
arithmetics(:|, other)
end
def uniq_words(nth, *base)
base.inject(self) { |_self, b| _self - b.select(/./) { |freq| freq >= 10 } }.top_by_frequency(nth)
end
protected :words
private
def input_to_string(input, inner_call)
case input
when /^http/
begin
open(input) { |f| return f.read }
rescue Exception => e
puts e
exit
end
when String
begin
File.open(input, "r") { |f| return f.read }
rescue
STDERR.puts "Argument has assumed as a text string" unless inner_call
input
end
when ARGF.class
input.read
else
raise "Wrong argument. ARGF, file or string are acceptable."
end
end
def take_by_value(nth, sort_opt, &blk)
val = lambda { |key, val| val }
take_by_key_or_val(nth, sort_opt, val, &blk)
end
def take_by_key(nth, sort_opt, &blk)
key = lambda { |key, val| key }
take_by_key_or_val(nth, sort_opt, key, &blk)
end
def take_by_key_or_val(nth, sort_opt, by)
@freq_dic.select { |key, val| block_given? ? yield(val) : val }.take_by(nth) { |key, val| sort_opt[by[key, val]] }
end
def arithmetics(op, other)
result = (@words.send op, other.words).join(" ")
WordDictionary.new(result, '', true)
end
end
def pretty_print(data)
max_stars = 60
max_value = data.max_by { |word, freq| freq }.slice(1)
data.each do |word, freq|
stars = "*" * (max_stars * (freq/max_value.to_f)).ceil
printf "%5d:%-5s %s\n", freq, word, stars
end
end
if $0 == __FILE__
base = WordDictionary.new('public/base.txt')
alice = WordDictionary.new('public/alice.txt', "Alice's Adventures in Wonderland")
jp_history = WordDictionary.new('public/japanese_history.txt')
p alice.uniq_words(40, base)
p jp_history.uniq_words(40, base)
end最後に
英文小説の最頻出ワードを見つける旅はこれで終わりです。長い道のりでした。でもわたしは楽しめました。そして大変勉強になりました。
そう、このチュートリアルは皆様のためにではなく、実は私自身のために書かれたものなのです。Rubyのエキスパートが余裕を持って書いたものではなく、プログラム新人が学び試行錯誤しながら、その知力の限界を引き出して書いたものなのです。
でも一方で、このチュートリアルを役に立ったと言ってくれる人がいつか現れると信じてもいるのです。それがRubyを学びその成果をブログで公開するわたしのエンジンになっているのです。
最後にこのWordDictionaryクラスを使ったWebアプリケーションを構築してみました。これが今回のチュートリアルの一応の成果です。よろしければアクセスしてみてください。

機能は次の3つだけです。
- いくつかの英文小説の特徴、つまりタイトル、総単語種数(Total Words in Kind)、最頻出ワードtop30(Most Used Words)、最ワード長top10(Longest Words)、特徴ワード20(Characteristic Words)を表示します。
- 小説タイトルをクリックするとその文章の頁に遷移します。
- 右端の入力欄に英文または英文の置かれたURLを入れることで、その文章の特徴を抽出して表示します。
サイトの構築には、SinatraというWebフレームワークと、herokuというサービスを使いました。
すべてのスクリプトは以下に公開しています。
電子書籍「Rubyチュートリアル ~英文小説の最頻出ワードを見つけよう!」EPUB/MOBI版
このリンクはGumroadにおける商品購入リンクになっています。クリックすると、オーバーレイ・ウインドウが立ち上がって、この場でクレジットカード決済による購入が可能です。購入にはクレジット情報およびメールアドレスの入力が必要になります。購入すると、入力したメールアドレスにコンテンツのDLリンクが送られてきます。
=== Ruby関連電子書籍100円で好評発売中! ===



blog comments powered by Disqus
