
Excelデータを最速でWebアプリ(Heroku)にする109のステップ CtoD: a tool for exporting csv data to database with Ruby
ローカルには映画の視聴記録とか食べ歩きのお店評価とか投資履歴とかガラクタコレクションリストとかの自身の活動記録的なデータが溜まります。そしてどういうわけかそれらのデータは大概表計算ソフト「Excel」の上に置かれているのです。その結果、溜めたはいいが有効に活用されない、場合によっては見ることすらしないという事態に陥ります。それらのデータが本来的に置かれる場所が「データベース」であり、その活用によりデータ価値が向上するということに誰も異論はないとしても、データはExcelに置かれるのです。
理由は一つ。そう、データベースは敷居が高いのです。
データベースの敷居が下がれば、みんながローカルのデータをもっともっと大量に公開して世の中はもっと便利になるに違いありません。
まあ、実際のところはよくわかりませんが。
そんなわけで…
データベースの敷居を下げるべく、CSVデータを簡単にデータベース化するRuby製のツールCtoDを作りました:-)
テストがないとか自分にデータベース周りの知識がないとかで変なコトやってる可能性大ですが、自分の環境では一応動いているので公開します。
以下では、CtoDとSiantraを使ってNumbers上のデータをHeroku上でWebアプリ化する手順を書きます。ExcelではなくAppleのNumbersです。環境はMac OSX(Mavericks)です。Herokuにアカウントがあることを前提とします。Windowsでの手順はわかりません。Excelとか言っておいてごめんなさいm(__)m
STEP0: Numbers上にデータを用意する
Numbers上に以下のような映画視聴記録データがあると仮定します。
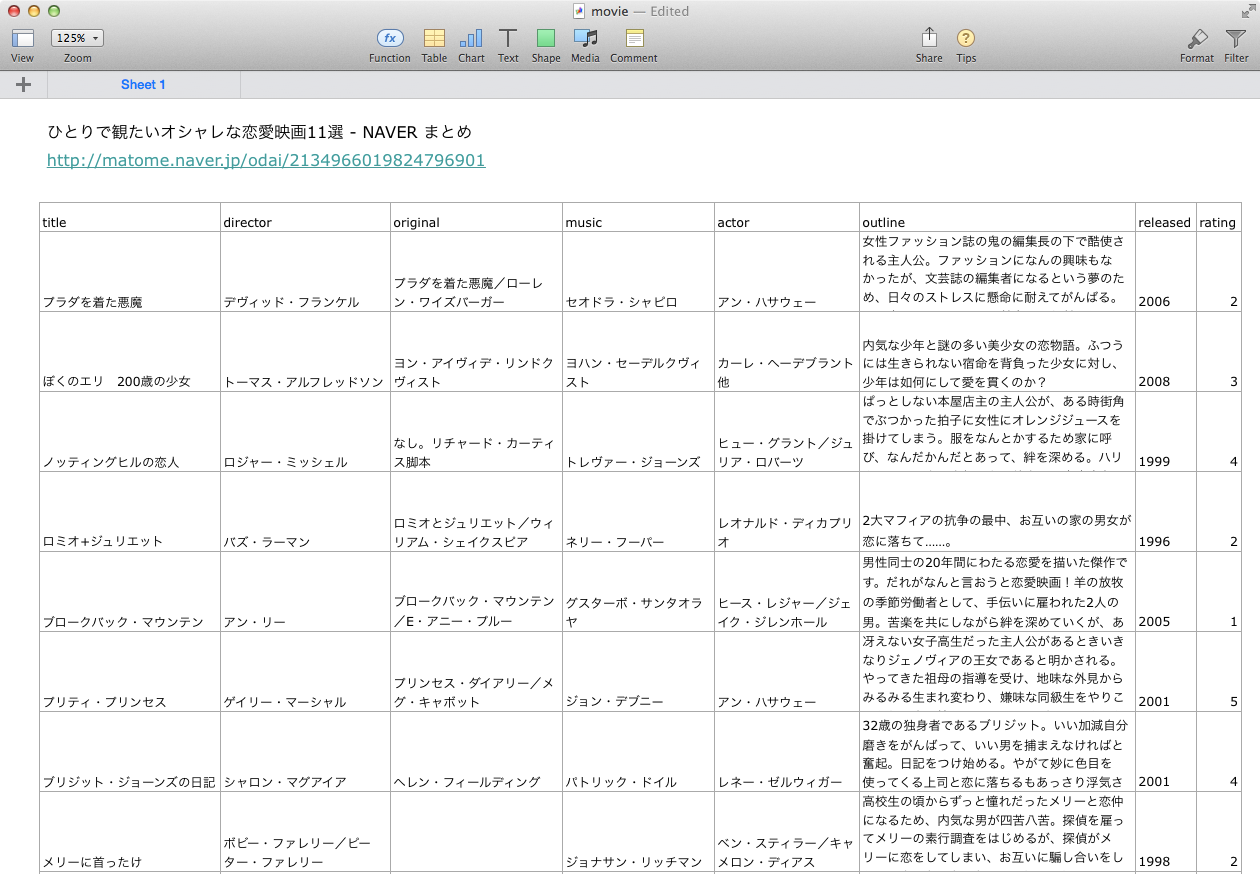
例を作るため、ここでは公開されている以下の映画データを利用させて頂きましたm(__)m
STEP1: NumbersデータをCSVにする
Numbersのエクスポート機能を使ってデータをCSV形式にします。CSV化に当たり以下のような制約があります。
- CSVのファイル名は英単語の複数形であること
- 余分な行・列が含まれていないこと
- 各フィールドのヘッダー名が各異なる英文字であること
- idフィールドは自動生成されるので削除すること
- 日付のフィールドは
YYYY-MM-DDまたはYYYY/MM/DDの形式とすること- 論理値の値は’true’または’false’にすること
- 先頭レコードの各フィールドをできるだけ空欄にしないこと
ここではファイル名をmovies.csvとし、/mymovieディレクトリに保存します。
STEP2: Postgresをインストールする
HerokuのデータベースがPostgresなのでローカルの環境にもこれをインストールします。Macで最も簡単な方法はPostgres.appをインストール方法でしょう。
Herokuにデプロイせず、ローカルで楽しむだけならsqlite3(Macにプリインストール)、mysqlなどを使うこともできます(その他のデータベースでは試していません)。
(追記:2013-11-13) Postgresをインストールせずにローカルでsqlite3を使う場合でも、Herokuへのデプロイ・運用は可能です。その場合はSTEP4に進んでください。
STEP3: movieデータベースを作る
Postgresのインストールで、psqlというコマンドラインツールが使えるようになります。これを使ってデータベースを作ります。名前はmoviesとします。Postgresが起動していることを確認した上で以下を実行します。
/mymovie% psql
psql (9.3.0)
Type "help" for help.
keyes=# create database movies;
CREATE DATABASE
データベースの生成を確認してquitします。
keyes=# \list
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+---------+-------+-------------------
movies | keyes | UTF8 | C | C |
postgres | keyes | UTF8 | C | C |
keyes=#\q
/mymovie%
STEP4: CtoDでCSVからデータベース・テーブルを作る
CtoD gemをインストールします。
/mymovie% gem install ctoD
Fetching: ctoD-0.0.1.gem (100%)
Successfully installed ctoD-0.0.1
1 gem installedこれでターミナル上でctoDコマンドが使えるようになります。
ctoDコマンドで表示されるhelpを確認した上で、exportサブコマンドを実行します。exportサブコマンドは引数で渡されたcsvファイルを読み取って、ターゲットデータベース上にテーブルを作成し、そこにcsvのデータをエクスポートします。
/mymovie% ctoD export movies.csv postgres://localhost/movies
Table 'movies' created at postgresql://localhost/movies.
CSV data exported successfully.上で見るようにデータベースの指定は、そのスキーマ、ホスト、DB名を含むアドレスで行います。データベースへのログイン情報が必要な場合は以下のようにします。
mysql://root:mypassword@localhost/movies
sqlite3の場合は以下のようにデータベースファイルの保存先を絶対パスで指定します。
sqlite3://localhost//Users/yourname/path/to/movies.sqlite3
localhostの後のスラッシュが2つ必要な点気をつけてください。
CtoDは内部的にはActiveRecordを使っています。CtoDのもう少し詳しい説明は別途記事にします。
psqlでmoviesテーブルが生成されているか確認します。
/mymovie% psql movies
psql (9.3.0)
Type "help" for help.
movies=# \d movies;
Table "public.movies"
Column | Type | Modifiers
------------+-----------------------------+-------------------------------------
id | integer | not null default nextval('movies_id_seq'::regclass)
title | character varying(255) |
director | character varying(255) |
original | character varying(255) |
music | character varying(255) |
actor | character varying(255) |
outline | text |
released | integer |
rating | integer |
created_at | timestamp without time zone | not null
updated_at | timestamp without time zone | not null
Indexes:
"movies_pkey" PRIMARY KEY, btree (id)
データがインポートされているか確認します。
movies=# select title, actor from movies;
title | actor
------------------------------+------------------------------------------------
プラダを着た悪魔 | アン・ハサウェー
ぼくのエリ 200歳の少女 | カーレ・ヘーデブラント他
ノッティングヒルの恋人 | ヒュー・グラント/ジュリア・ロバーツ
ロミオ+ジュリエット | レオナルド・ディカプリオ
ブロークバック・マウンテン | ヒース・レジャー/ジェイク・ジレンホール
プリティ・プリンセス | アン・ハサウェー
ブリジット・ジョーンズの日記 | レネー・ゼルウィガー
メリーに首ったけ | ベン・スティラー/キャメロン・ディアス
ゴースト ニューヨークの幻 | パトリック・スジェイジ/デミ・ムーア
パールハーバー | ジョシュ・ハートネット/ケイト・ベッキンセール
猟奇的な彼女inNY | ジェシー・ブラドフォード/エリシャ・カスバート
(11 rows)
movies=# \q
/mymovie%
上手くいっているようです。
STEP5: SinatraでWebアプリを作る
次に、このデータをブラウザ上で表示できるようWebアプリを作ります。Sinatra + hamlを使います。
app.rbという名称で以下のようなコードを書きます。
#app.rb
require 'sinatra'
require 'haml'
require 'ctoD'
class Movie < ActiveRecord::Base
end
configure :production do
CtoD::DB.connect(ENV['DATABASE_URL'])
end
configure :development do
CtoD::DB.connect('postgres://localhost/movies')
end
get '/' do
redirect '/movie'
end
get '/movie' do
@movies = Movie.all
haml :index
end
get '/movie/:id' do |id|
@movie = Movie.find(id)
haml :movie
end
helpers do
def columns
Movie.column_names.reject { |n| n.match /_at$/ }
end
endActiveRecord::Baseを継承したMovieクラスを作ります。クラス名はテーブル名の単数形にします。CtoD::DB.connectを使ってデータベースに接続します。本番環境ではENV['DATABASE_URL']を渡します。/movieパスでデータ一覧を、/movie/:idで個別ページを表示するようにします。CRUDのCUD、ログイン認証については実装を割愛します:-)
ここではテンプレートはinline templateを使います。同じファイルの__END__以下に次のコードを書き足します。
__END__
@@layout
!!!
%html
%head
%meta{charset:'utf-8'}
%title Movie Reviews
%link{:href=>"//netdna.bootstrapcdn.com/bootstrap/3.0.2/css/bootstrap.min.css", :rel=>"stylesheet"}
%script{:src=>"//netdna.bootstrapcdn.com/bootstrap/3.0.2/js/bootstrap.min.js"}
%body
.container
!= yield
@@index
%h2 Movie Reviews
%table.table.table-striped.table-hover.table-bordered
%thead.header
- columns.each do |t|
%th= t
%tbody
- @movies.each do |st|
%tr
- columns.each do |t|
- if t=='title'
%td
%a{href:"/movie/#{st.id}"}= st[t]
- else
%td= st[t]
@@movie
%h3= @movie.title
%table.table
- columns.each do |t|
%tr
%td= t
%td= @movie[t]Twitter bootstrapを読み込んでいます。
STEP6: ローカルで起動してみる
用意ができたのでまずはローカルで起動してみます。
/mymovie% ruby app.rb
== Sinatra/1.4.4 has taken the stage on 4567 for development with backup from Thin
>> Thin web server (v1.5.1 codename Straight Razor)
>> Maximum connections set to 1024
>> Listening on localhost:4567, CTRL+C to stopまずはトップページ。
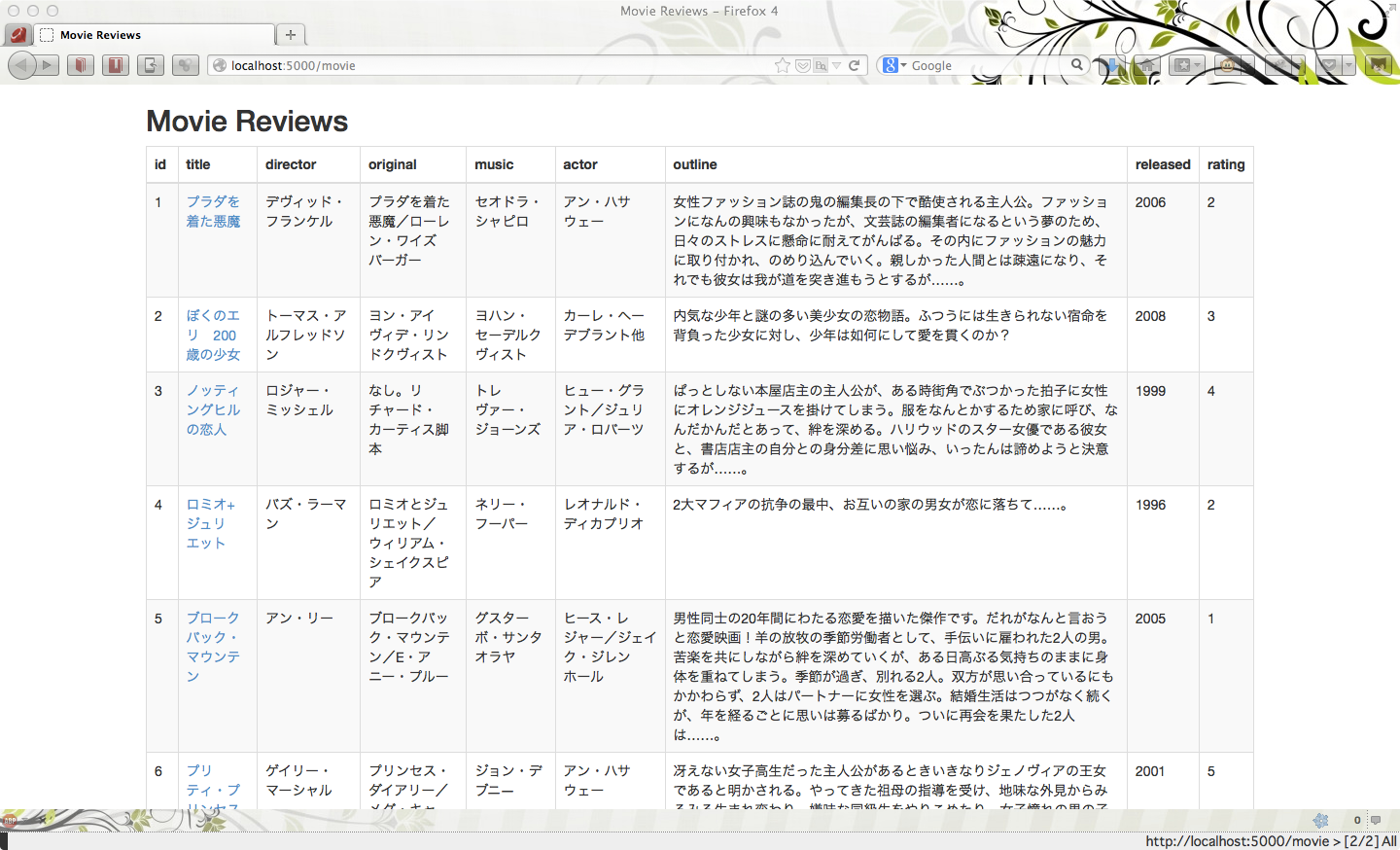
タイトルをクリックすれば個別ページに遷移します。
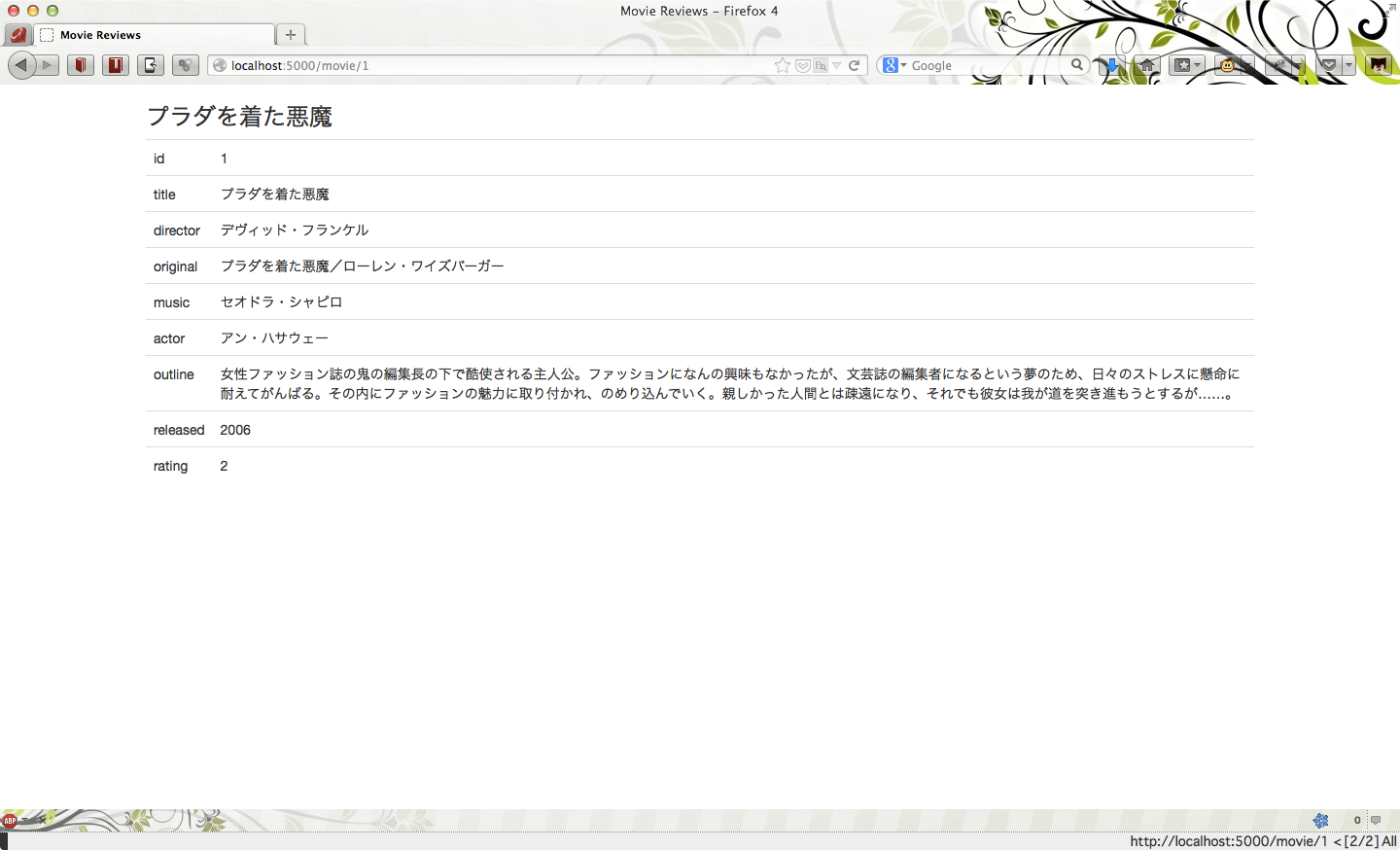
いいですね!
STEP7: Heroku用のファイルを用意する
さて、引き続きHerokuにデプロイするためのファイルを用意します。デプロイにはGemfileとProcfileが必要です。
#Gemfile
source 'https://rubygems.org'
ruby '2.0.0'
gem 'sinatra'
gem 'haml'
gem 'ctoD'
gem 'pg'pgはPostgreのインタフェースです。bundle installします。
mymovie% bundle install
Fetching gem metadata from https://rubygems.org/...........
Fetching gem metadata from https://rubygems.org/..
Resolving dependencies...
Using i18n (0.6.5)
Using multi_json (1.8.2)
Using activesupport (3.2.15)
Using builder (3.0.4)
Using activemodel (3.2.15)
Using arel (3.0.2)
Using tzinfo (0.3.38)
Using activerecord (3.2.15)
Using thor (0.18.1)
Using ctoD (0.0.1)
Using tilt (1.4.1)
Using haml (4.0.4)
Using pg (0.17.0)
Using rack (1.5.2)
Using rack-protection (1.5.1)
Using sinatra (1.4.4)
Using bundler (1.3.5)
Your bundle is complete!
Use `bundle show [gemname]` to see where a bundled gem is installed.次にProcfileを作ります。
#Procfile
web: bundle exec ruby app.rb -p $PORTこのファイルによりforeman startでローカルで起動するようになります。デフォルトポートは5000番です。
/mymovie% foreman start
21:38:45 web.1 | started with pid 84425
21:38:48 web.1 | [2013-11-10 21:38:48] INFO WEBrick 1.3.1
21:38:48 web.1 | [2013-11-10 21:38:48] INFO ruby 2.0.0 (2013-02-24) [x86_64-darwin12.2.0]
21:38:48 web.1 | == Sinatra/1.4.4 has taken the stage on 5000 for development with backup from WEBrick
21:38:48 web.1 | [2013-11-10 21:38:48] INFO WEBrick::HTTPServer#start: pid=84425 port=5000STEP8: Herokuにデプロイする
作成したファイルを確認します。
/mymovie% tree
.
├── Gemfile
├── Gemfile.lock
├── Procfile
├── app.rb
├── movies.csv
0 directories, 5 filesこれらのファイルをgitで管理します。
/mymovie% git init
/mymovie% git add .
/mymovie% git commit -m 'init'heroku createコマンドでHerokuにアプリを作ります。アプリ名を渡さなければHerokuが自動生成します。
/mymovie% heroku create
Creating serene-retreat-5896... done, stack is cedar
http://serene-retreat-5896.herokuapp.com/ | git@heroku.com:serene-retreat-5896.git
Git remote heroku addedデプロイします。
/mymovie% git push heroku master
Counting objects: 7, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (7/7), 4.18 KiB, done.
Total 7 (delta 0), reused 0 (delta 0)
-----> Ruby app detected
-----> Compiling Ruby/Rack
-----> Using Ruby version: ruby-2.0.0
-----> Installing dependencies using Bundler version 1.3.2
New app detected loading default bundler cache
Running: bundle install --without development:test --path vendor/bundle --binstubs vendor/bundle/bin --deployment
Fetching gem metadata from https://rubygems.org/..........
Fetching gem metadata from https://rubygems.org/..
.
.
.この段階ではまだデータの準備ができていないのでサイトを開いてもInternal Server Errorになりますが、データベースの下準備ができていることはheroku configで確認できます。
% heroku config
=== serene-retreat-5896 Config Vars
DATABASE_URL: postgres://kdgrmzoforanpf:uyoucPUDBztg_3mlx9RGTnAJw8@ec2-107-20-214-225.compute-1.amazonaws.com:5432/da7n8egah2mc0j
HEROKU_POSTGRESQL_IVORY_URL: postgres://kdgrmzoforanpf:uyoucPUDBztg_3mlx9RGTnAJw8@ec2-107-20-214-225.compute-1.amazonaws.com:5432/da7n8egah2mc0j環境変数DATABASE_URLにPostgresがセットされているのが分かります。
STEP9: Heroku上でCtoDを使ってmovieデータをインポートする
ローカルでしたのと同じ方法で、CtoDを使い、Heroku上のPostgresにmoviesテーブルを作ってmovie.csvのデータを移管します。
heroku run bashでheroku上のshellに入ります。
/mymovie% heroku run bash
Running `bash` attached to terminal... up, run.5226
~ $ ls
app.rb bin Gemfile Gemfile.lock movies.csv Procfile tmp vendor
~ $ ctoD
Commands:
ctoD create_table CSV DATABASE # Create a database table for CSV
ctoD export CSV DATABASE # Export CSV data to DATABASE
ctoD help [COMMAND] # Describe available commands or one specific command
~ $ echo $DATABASE_URL
postgres://sohuhqdovqldxg:SLoVuN9ebo-xxIP-B42h4rGLFN@ec2-23-23-81-171.compute-1.amazonaws.com:5432/d5e2t0r73fspnb
ctoD exportを実行します。
~ $ ctoD export movies.csv $DATABASE_URL
Table 'movies' created at postgresql://sohuhqdovqldxg:SLoVuN9ebo-xxIP-B42h4rGLFN@ec2-23-23-81-171.compute-1.amazonaws.com:5432/d5e2t0r73fspnb.
CSV data exported successfully.
~ $ exit
exit
/mymovie%
さあ、これでmovieデータがデータベースに収まりました。完成したサイトを見てみます。
/mymovie% heroku open
Opening serene-retreat-5896... done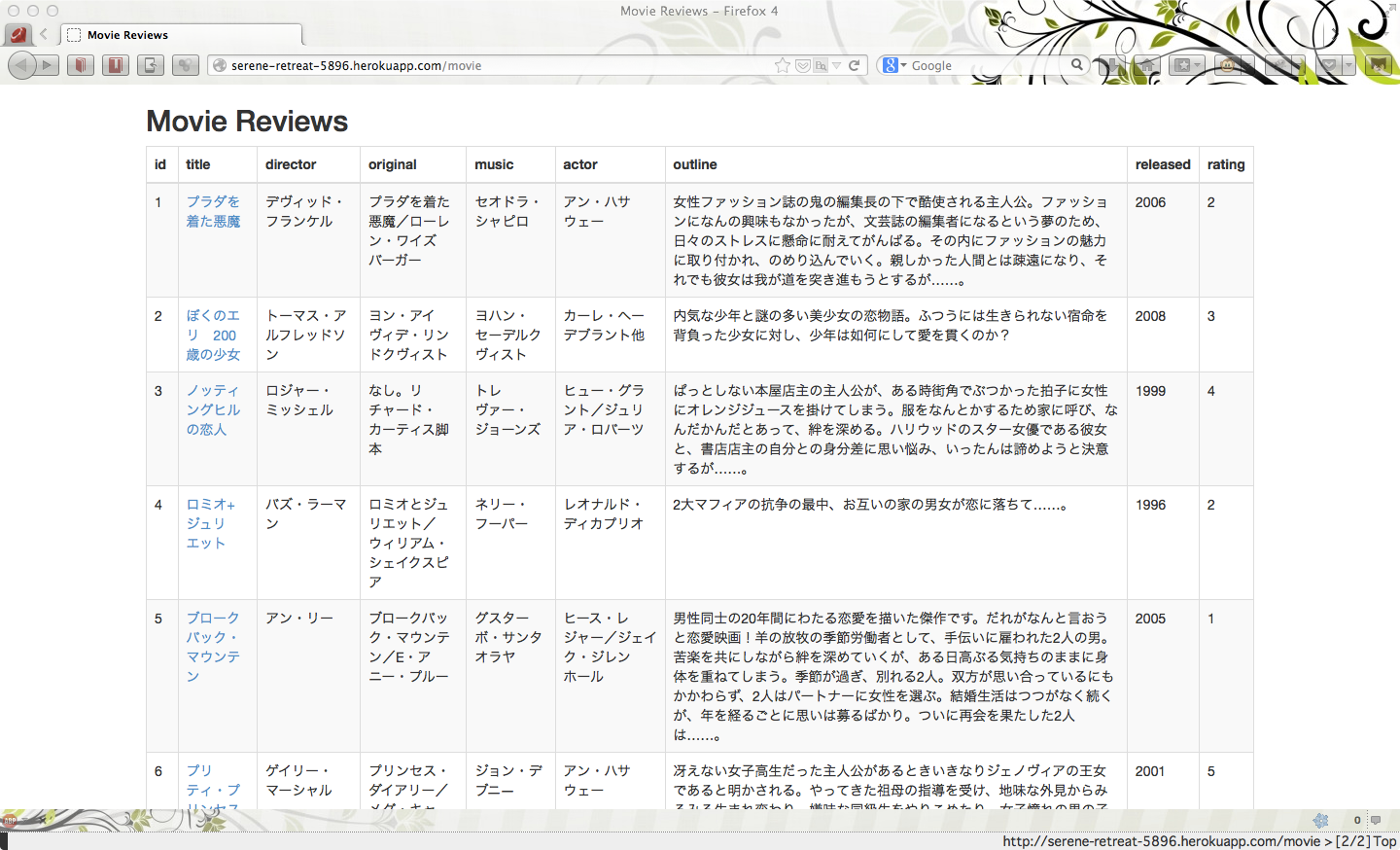
いいですね!
データベースの敷居、少しは下がりましたかね?
以下のSTEP9および10は、上記STEP9で行ったHeroku上でCtoDを実行する方法を使わずに、ローカルのPostgresにあるデータをHeroku上のPostgresに移管する方法を使う場合のステップです。
STEP9: movieデータをダンプしてDropboxにアップする
次にローカルのmovieデータをHeroku上のデータベースに移管する手順を説明します。詳細はこちらで。
Importing and Exporting Heroku Postgres Databases with PG Backups | Heroku Dev Center
まずはpg_dumpコマンドを使ってデータをダンプします。
/mymovie% pg_dump -Fc --no-acl --no-owner -h localhost movies > movies.dumpHeroku側からこのダンプファイルにHTTPアクセスできるようにします。ここではDropboxを使います。ファイルをDropboxのPublicフォルダに移動します。
/mymovie% mv movies.dump ~/Dropbox/PublicDropboxのWebサイトに行き該当ファイルを右クリックしてCopy public linkをコピーしておきます。
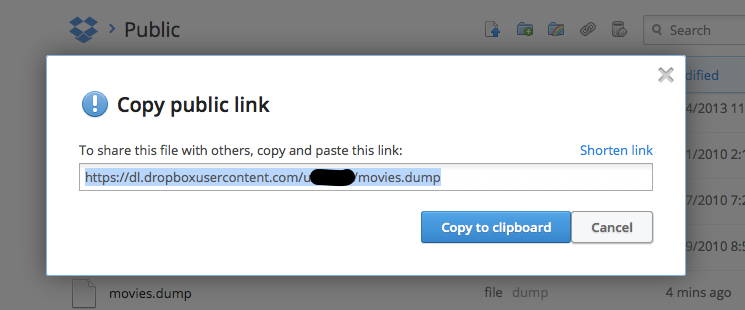
STEP10: herokuにリストアする
Herokuへデータを取り込むためPG Backups add-onを使います。heroku addons:addコマンドで使えるようにします。
/mymovie% heroku addons:add pgbackups
Adding pgbackups on serene-retreat-5896... done, v6 (free)
You can now use "pgbackups" to backup your databases or import an external backup.
Use `heroku addons:docs pgbackups` to view documentation.先ほど取得したDropbox上のurlを引数にしてそのデータをHeroku上のデータベースにリストアします。途中で確認がでますので、アプリ名を入れて対応します。
/mymovie% heroku pgbackups:restore DATABASE_URL 'https://dl.dropboxusercontent.com/u/xxxxx/movies.dump'
HEROKU_POSTGRESQL_IVORY_URL (DATABASE_URL) <---restore--- movies.dump
! WARNING: Destructive Action
! This command will affect the app: serene-retreat-5896
! To proceed, type "serene-retreat-5896" or re-run this command with --confirm serene-retreat-5896
> serene-retreat-5896
Retrieving... done
Restoring... doneこれでHeroku上にデータが移管されました。
(追記:2013-11-14) CtoDのもう少し詳しい説明を書きました。
(追記:2013-11-12) Heroku上でCtoDを実行する新たなSTEP9を追記しました。
=== Ruby関連電子書籍100円で好評発売中! ===



blog comments powered by Disqus
